Design by @imrahelk
안녕하세요. 안피곤입니다.
크롤링한 스팀잇 데이터를 이용하여 본래 목적인 태그별 통계를 계산해보겠습니다. 사실 통계 시스템 구현에 prisma는 비효율적인 부분이 있는 것 같습니다. ㅋ
개인적으로 prisma에 Insert All 기능이 없는 것이 가장 아쉽습니다. 그리고 Aggregations comming soon 입니다. ㅠ
아래에서는 수집한 데이터를 이용하여 보상금액순, 댓글순, 보팅순, 포스팅수를 집계할 것입니다. 하지만 아직 GraphQL이나 prisma에 익숙하지 않아 매우 단순하게 구현하였습니다.
시리즈글 프리즈마(Prisma) 사용하기 #1 : 시작하기 프리즈마(Prisma) 사용하기 #2 : Insert 하기
시리즈 글을 자동으로 모아주는 툴이 있으면 정말 좋을 것 같습니다. @nhj12311님 어디 가셨나요? ㅠㅠ
*
필드를 추가하기 위해 datamodel.prisma 을 수정하였습니다. 보팅과 댓글 개수를 파악하기 위한 vote_count와 comment_count 필드가 추가되었습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 type Post { id: ID! @id post_id: Float ! @unique author: String! author_reputation: Float ! permlink: String! category: String! title: String! body: String! tags: [String!]! @scalarList(strategy: RELATION) image: String created: Float ! total_payout_value: Float @default(value: 0) curator_payout_value: Float @default(value: 0) pending_payout_value: Float @default(value: 0) vote_count: Int @default(value: 0) comment_count: Int @default(value: 0) }
1 $ prisma deploy && prisma generate
index.js 의 main() 함수를 수정합니다. 데이터 100건을 loop 돌면서 등록합니다. 그리고 prisma.upsertPost() 함수를 사용하여 기존의 데이터가 있으면 수정 or 없으면 신규 등록하도록 하였습니다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 async function main() { const opts = { tag: 'kr' , limit: 100 } const discussions = await client.database.getDiscussions('created' , opts); for (let i = 0 , l = discussions.length; i < l; i++) { const { post_id, author, author_reputation, permlink, category, title, body, json_metadata, created, total_payout_value, curator_payout_value, pending_payout_value, active_votes, children } = discussions[i]; const { tags, image: images } = JSON .parse(json_metadata); const image = images && images.length && images[0 ] || null ; const vote_count = active_votes.filter(e => e.percent > 0 ).length; try { const result = await prisma.upsertPost({ where: { post_id }, update: { author_reputation, title, body, tags: { set: tags }, image, total_payout_value: parseFloat (total_payout_value), curator_payout_value: parseFloat (curator_payout_value), pending_payout_value: parseFloat (pending_payout_value), vote_count, comment_count: children }, create: { post_id, author, author_reputation, permlink, category, title, body, tags: { set: tags }, image, created: parseFloat (dateFormat(new Date (`${created}`), 'yyyymmddHHMMss' )), total_payout_value: parseFloat (total_payout_value), curator_payout_value: parseFloat (curator_payout_value), pending_payout_value: parseFloat (pending_payout_value), vote_count, comment_count: children } }); console .log(result.id); } catch (error) { console .error(error, JSON .stringify(error)); } } }
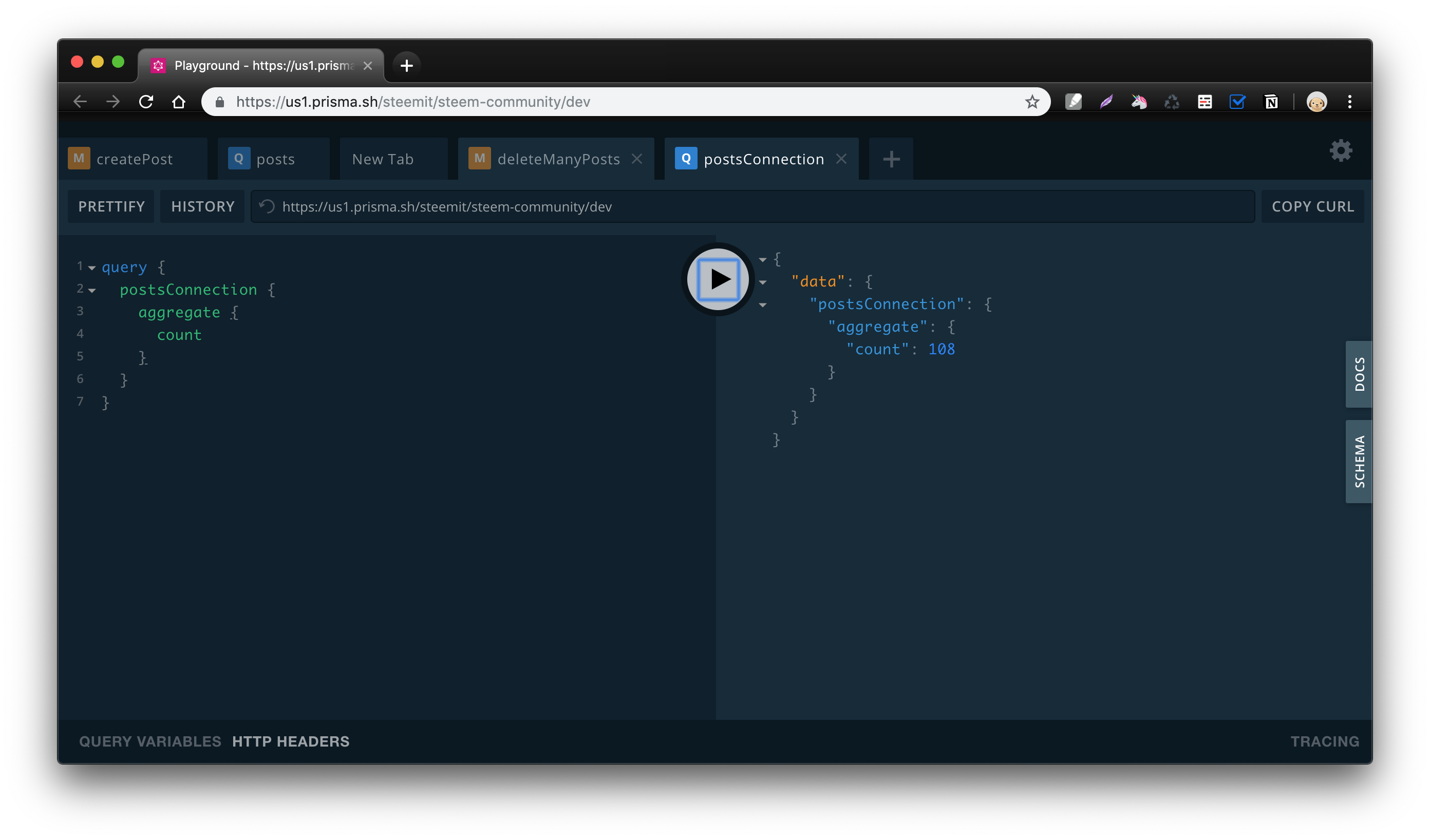
Prisma Playground 에서 쿼리를 날려 전체 데이터수를 확인해봅니다.
1 2 3 4 5 6 7 query { postsConnection { aggregate { count } } }
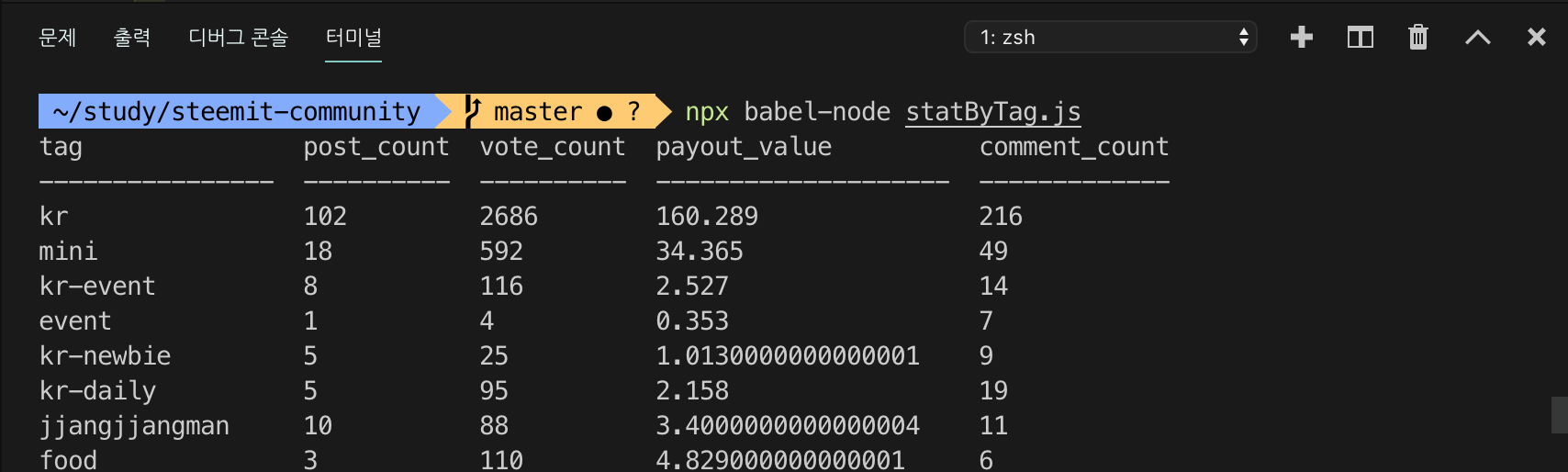
기간 일주일(2019/04/22 ~ 2019/04/28 )의 데이터를 이용하여 보상금액, 댓글, 보팅, 포스팅 개수 계산합니다. 데이터가 100건 밖에 없어서 일주일분의 데이터가 아닐 수도 있습니다.
statByTag.js
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 import { Client } from 'dsteem' ;import { prisma } from './generated/prisma-client' ;import 'console.table' ;const client = new Client('https://api.steemit.com' );async function main() { try { const result = await prisma.posts({ where: { created_gte: 20190422000000 , created_lte: 20190428595959 } }).$fragment(` fragment TagsInPosts on Posts { tags total_payout_value curator_payout_value pending_payout_value vote_count comment_count } `); const stat = result.reduce((acc, val) => { const { vote_count, comment_count, tags } = val; const payout_value = val.curator_payout_value + val.pending_payout_value + val.total_payout_value; tags.filter(tag => Boolean (tag)).forEach(tag => { if (acc.hasOwnProperty(tag)) { acc[tag].post_count += 1 ; acc[tag].vote_count += val.vote_count; acc[tag].payout_value += payout_value; acc[tag].comment_count += val.comment_count; } else { acc[tag] = { post_count: 1 , vote_count, payout_value, comment_count, }; } }); return acc; }, {}); console .table(Object .keys(stat).map (key => ({ tag: key, ...stat[key] }))) } catch (error) { console .error(error); } } main() .then (() => { process.exit(0 ) }) .catch (e => console .error(e))
1 $ npx babel-node statByTag
원사마님이 알려주신 console.table을 이용하여 출력해보았습니다.
2019/04/22 ~ 2019/04/28 )프로그램을 돌려놓고 포스팅을 작성하는 중에 일주일 정도의 데이터가 수집되었습니다. 일주일 분량의 데이터를 수집하는데 약 30분 정도 소요된 것 같습니다. 그리고 태그는 중복으로 사용가능하기 때문에 중복 데이터가 포함되어 있습니다.
정렬: 포스팅 수
No
태그
포스팅수
보팅수
보상금액
댓글수
1
kr
2028
75811
5678.558
12501
2
busy
720
36089
2766.685
6258
3
jjm
421
22915
1888.191
4513
4
mini
265
11850
1035.02
2382
5
tasteem
185
9501
909.401
2385
6
life
176
7626
677.482
1020
7
kr-newbie
173
2200
142.994
892
8
tasteem-kr
169
8242
838.433
2140
9
jjangjjangman
168
3891
225.33
734
10
thegivingtree
149
3362
168
1106
정렬: 보상 금액
No
태그
포스팅수
보팅수
보상금액
댓글수
1
kr
2028
75811
5678.558
12501
2
busy
720
36089
2766.685
6258
3
jjm
421
22915
1888.191
4513
4
mini
265
11850
1035.02
2382
5
tasteem
185
9501
909.401
2385
6
tasteem-kr
169
8242
838.433
2140
7
life
176
7626
677.482
1020
8
muksteem
130
6412
563.322
1606
9
steemmonsters
93
5240
353.713
625
10
steemit
92
2811
332.537
484
정렬: 댓글 수
No
태그
포스팅수
보팅수
보상금액
댓글수
1
kr
2028
75811
5678.558
12501
2
busy
720
36089
2766.685
6258
3
jjm
421
22915
1888.191
4513
4
tasteem
185
9501
909.401
2385
5
mini
265
11850
1035.02
2382
6
tasteem-kr
169
8242
838.433
2140
7
muksteem
130
6412
563.322
1606
8
kr-series
71
4911
306.743
1301
9
tripsteem
99
4783
318.564
1118
10
thegivingtree
149
3362
168
1106
여기
*
영화, 방송&연예, 게임, 애니메이션, 만화, 도서, 음악, 공연&전시, 음식, 애완반려동물, 여행, 사진, 패션&뷰티, 연애, 개그, 일상, 육아, IT, 얼리어답터, 지름, 자동차, 스포츠, 뉴스비평, 인문사회, 역사, 세계, 과학, 토이
“[머신러닝] 스팀잇 글 분류하기 (첫번째 시도)” . 결과적으로 저의 머신러닝의 이해도가 매우 낮아 구현하지 못하였습니다. 이번에는 좀더 단순하게 접근하기로 하였습니다. 이번에 한다면 스팀잇 글 분류하기 두 번째 시도가 되겠네요.